Колекція комп'ютерів
Про що
Про колекцію комп'ютерів, шину PCIe і побутову електроніку DIY PC.
Даний текст — це багатоцільова спроба розповісти історію комп'ютерної техніки: задокументувати розвиток та виділити генеалогію, спробувати розповісти про комп'ютер з погляду споживчої електроніки, сформувати список найкращих колекційних екземплярів для будівництва шоурумів чи ютуб каналів.
Історія цього тексту
Цей текст з'явився завдяки носталігії за PC культурою та повернення до її DIY витоків. Тепер, коли прийшла старість, можу собі дозволити відтворити колекцію комп'ютерів, якими володів у цьому житті. Авторський період 2010-2018 років, який вимагав лише друкарську машинку та процесор рівня ARM32, давно позаду і тепер хочеться зайнятися справжніми обчислювальними завданнями, які потребують ресурсів рівня робочих станцій. В основному, я планую зайнятися системами зберігання на SSD/NVMe з використанням spdk та RocksDB/NVMe, а для будівництва цих масивів потрібні бажано невіртуальні диски, і більше, адже йдеться про 32 лінії PCI Express (PCIe) для дискової підсистеми. Тому грошей все це споживатиме багато, особливо з урахуванням бажання працювати на сучасному залізі версії PCIe 4.0. Також хочу поекспериментувати із системами індексації, які працюють у просторі GPU (такими як Uber AresDB). Для цього потрібні відеокарти з максимальною кількістю пам'яті, а це зазвичай карти рівня Titan. На щастя, nVidia з анонсом 30-ї серії знизила ціни на такі карти втричі (до $1500 за 24ГБ). Починаючи з планів купівлі цих сучасних дорогих компонентів, я плавно увійду в рестроспективу комп'ютерної техніки (у тому числі і свою особисту) і простежу історію її розвитку з точки зору стандарту PCIe, перша версія якого була створена в 2003 році. Все що до PCIe 2.0 не є для мене архівною цінністю, а лише колекційною.
Визначення, що таке комп'ютер
Спочатку хочу розповісти, що таке комп'ютер, з погляду яких критеріїв ми його представляємо в цьому випуску. Комп'ютер — це система з таких пристроїв: 1) процесор; 2) пам'ять; 3) відеокарта; 4) диск; 5) мережна картка; 6) система живлення та інші технічні модулі; які з'єднані певним чином (зазвичай це шина або безпосереднє з'єднання точка-точка чере хаб (InfiniBand, PCIe, QPI, HyperTransport, etc.) Ці з'єднання є видимими доріжками на материнській платі, де компонується вся електроніка. У разі PCIe такий хаб називається кореневим комплексом, куди сходяться всі лінії PCIe. Основний принцип DYI електроніки — це максимально гнучка система розширень, що дозволяє додавати додаткові пристрої у вигляді плат у спеціальні місця, які підключені до шини або до хаба.
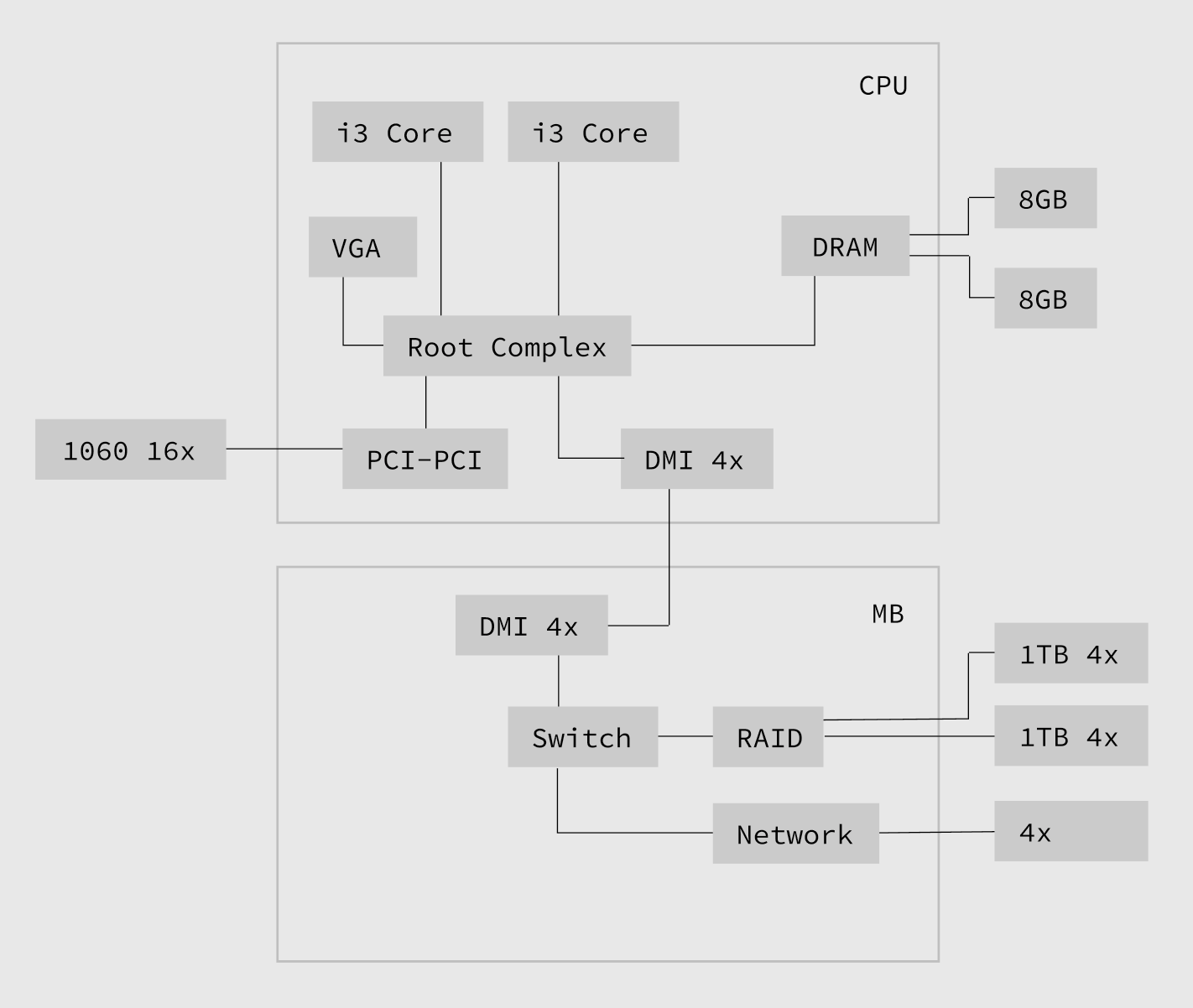
Види таких систем з'єднання компонентів називаються платформи. Розрізняють електричні (PCI, PCIe) і форм-факторні специфікації (PC/104, PCIe, mPCIe) платформ. PCIe переторилась на народну шину, яка стала стандартом де-факто при побудові датацентрів на ринку споживчої електроніки, витіснивши такі, раніше здавалося перспективні, стандарти, як InfiniBand чи RapidIO. Тепер PCIe використовується не тільки як з'єднання для масових (Intel і AMD), але і для інших (POWER9, ARM, RISC-V) мікропроцесорних архітектур.
Причини успіху PCIe
Причини такої популярності у справді гарній архітектурі електричної специфікації PCIe. На відміну від шини PCI, яка працює в загальному випадку як апаратний брокер каналів, PCIe є системою з кореневого комплексу і набору свічів, які можна підключати до нього каскадами. Ці пристрої можна налаштувати таким чином, щоб вони передавали дані один одному без участі посередників, запрограмувавши певним чином роутинг кореневого комплексу та системи PCIe свічів. Налаштовані певним чином, пристрої можуть використовувати спільну пам'ять і синхронізувати передачу даних між своїми буферами (DMA). Уявіть собі, що коли копіюється файл із диска на диск, CPU при цьому не пересилає жодних байтів. Приблизно те саме відбувається коли ви підключили дві відеокарти в режим SLI, вони спілкуються між собою по PCIe шині і здатні обмінюватися даними не вимагаючи відволікання процесора. Теоретично можливе підключення мережевих карт до будь-яких PCIe пристроїв, які сумісні за атрибутами підключення. Так, наприклад, мережева карта може складати пакети на диск автоматично без участі процесора, який можливо пізніше прочитає ці дані асинхронним чином. На жаль, архітектурні обмеження асинхронної природи TCP/IP не дозволяють робити такі чудеса в промисловому оточенні, для цього бажано повністю перепроектувати мережевий рівень. Завдяки цим особливостям, які раніше були доступні тільки в дорожчих оптичних стандартах типу InfiniBand, разом із зрозумілою та гнучкою системою масштабування, яка збільшує пропускну здатність двічі кожну версію, стандарт PCI Express протримався на ринку 17 років і ще протримається до моменту згортання закону Мура у 2024 році, коли ми досягнемо 2нм техпроцесу.
Проблеми масштабування PCIe в побутовій електроніці
За допомогою PCIe свічів розпаюється система вводу-виводу для підключення зовнішніх пристроїв. Зазвичай це підключається до пропрієтарного мосту та власного протоколу, що з'єднує кореневий комплекс із системою свічів для зовнішніх пристроїв. У випадку Intel такий протокол називається DMI і має архітектурне обмеження в 4/8 PCIe ліній і це не дає можливості будувати ефективні RAID NVMe масиви на Intel платформі, які зазвичай підключаються до пропрієтарного мосту для зовнішніх пристроїв через DMI bottleneck, яке, у свою чергу, підключено до кореневого комплексу – це перша проблема масштабування. На щастя на материнських платах розпаюються слоти для відеокарт, які під'єднані не через DMI інтерконнект, а безпосередньо до кореневого комплексу через високопродуктивний свіч, який зазвичай видно як PCI-to-PCI міст. Ви можете використовувати ці слоти для будівництва дискового масиву, але ви позбавляєтеся можливості використовувати GPU.
Друга проблема, яка може виникнути при масштабуванні дискового масиву — це дифіцит кількості PCIe ліній, які можна підключити до кореневого комплексу, які в сучасних системах знаходяться прямо в процесорі.
І нарешті існує третя проблема — це кількість ядер у процесорі. Якщо їх дуже мало, то кожне переривання на лінії вимагатиме відволікання процесора, що створюватиме багато зайвих переключень контекстів процесора та знижуватиме загальну теоретичну продуктивність. В ідеальній синхронній системі, для контролю кожної PCIe лінії потрібно виділяти окреме ядро процесора, щоб у разі переривання виниклого при обміні даними між пристроями це жодним чином не впливало на роботу інших потоків системи (QoS на рівні ліній PCIe). Таким чином хотілося б процесор у якого ядер вдвічі більше ніж PCIe ліній, тому що хочеться ще щось рахувати. Це, звичайно, оверкіл, але тільки так можна досягти гарантій рівня систем реального часу. Саме такі експерименти з дисковими масивами мене цікавлять як продовження мого дослідження високопродуктивних систем реального часу.
Системи
Свій архів я бачу як підрешітку кількох вимірів:
1) форм-фактор материнської плати: Mini-ITX, Micro-ATX, ATX, E-ATX;
2) тип мікропроцесорної архітектури: Intel, AMD, ARM, POWER9, RISC-V;
3) версії PCIe: 2.0 і 3.0+ з підтримкою NVMe M.2 дисків.
Перші колекційні, розглянуті мною, чіпсети — це перші чіпсети для PCIe, які мали графічну шину 16 ліній PCIe і були створені для перших процесорів Intel Core Duo. Збиратимемо комплектами по типу сокетів і чіпсетів: материнська плата, максимальний процесор, максимальний обсяг ОЗУ.
| Formfactor | mm | inches | Slots | Holes |
|---|---|---|---|---|
| Mini-ITX | 170 × 170 | 6.7 × 6.7 | 1 | 4 |
| Micro-ATX | 244 × 244 | 9.6 × 6.7—9.6 | 4 | 8 |
| ATX | 305 × 244 | 12 × 6.7—9.6 | 7 | 10 |
| E-ATX (SSI-CEB) | 305 x 267 | 12 x 9.6—10.5 (10.6 ASUS) | 7 | 8 |
| E-ATX (SSI-EEB) | 305 × 330 | 12 × 10.5—13 | 7 | 11 |
 |
 |
 |
 |
 | |
Багатосокетний період IA-32
Intel Core веде свою родословну від процесорів Intel Pentium Pro (P6). Покоління 32-бітних x86 процесорів Intel: 1) i386; 2) i486, перші мої процесори і перший Intel Datasheet, який я прочитав від першої до останньої сторінки, у мене були і чіпи Intel і AMD, а також версія AMD i586 з множником FSB x5); 3) Pentium (P5, 1994), який попав на ринок майже одночасно зі своїми серверними, більш потужними аналогами P6; 4) Pentium Pro (P6, 1995), Pentium II, Pentium III — ці процесори мали загальне архітектурне ядро, і розвивалися в основному в напрямку мультимедійних розширень (MMX, SSE, які стали прекурсорами сучасних інструкцій AVX, NNI), експериментах із сокетами і картриджами. У цей час з'явилися процесори Xeon, зі збільшеним об'ємом кеша.
У мене були двопроцесорні материнські плати для картриджних (TYAN Tiger 133, Slot 1) і сокетних (TYAN Thunder, Socket 370) P6 процесорів, колекція материнських плат на чіпсеті i440BX (ABit BP6, ASUS P2B), дві легендарні оверклокерскі плати TUSL2 і CUSL2.
| Platform | PCI | Expansions | Motherboard | Generation |
|---|---|---|---|---|
| PGA132 | 2.0 | 0/1/2/0 | PS/2 Model 70 T3 | 386DX 25MHz |
| Socket 3 | 2.0 | 0/1/2/0 | PS/2 Model 70 T4 | 486DX |
| Socket 7/MVP3 | 2.1 | 1/4/2/0 | FIC PA-2013 B1 | Pentium MMX |
| Socket 7/430TX | 2.1 | 0/4/4/0 | TX97-XE | Pentium MMX |
| Socket 8/440FX | 2.1 | 0/5/3/0 | P/I-P6NP5 | Pentium Pro |
| Slot 1/440BX | 2.1 | 1/5/2/0 | Tiger 100 S1832D | Pentium III |
| Slot 1/440BX | 2.1 | 1/4/2/3 | P2B-L | Pentium III |
| Slot 1/440BX | 2.1 | 1/4/2/3 | P2B-DS | Pentium III |
| Socket 370/815EP | 2.1 | 1/3/0/0 | CUSL2-C Black Pearl | Pentium III |
| Socket 370/815EP | 2.2 | 1/3/0/0 | TUSL2-C | Pentium III S |
| Socket 478/865PE | 2.3 | 1/3/0/0 | P4P800 SE | Pentium D/4/M |
| Socket 479/915GV | PCIe 1.1 | 0/1/0/0 | PTGV-DM | Pentium M |
| LGA775/945G | PCIe 2.3 | 1/2/0/0 | ConRoe945G-DVI | Pentium D/4/Core/Core2 |
| LGA775/945P | PCIe 2.3 | 2/3/0/0 | ConRoeXFire-eSATA2 | Pentium D/4/Core/Core2 |
П'ята за рахунком архітектура 32-бітових процесорів Intel — Pentium 4 NetBurst виявилася абсолютно невдалою, хотіли навіть змінити стандарт на блоки живлення (з ATX на BTX) через збільшені показники потужності, що розсіюється, але вернулися назад до архітектури P6 1995 року.
| Codename | Socket | Model | FSB | TDP |
|---|---|---|---|---|
| P55C 350nm | Socket 7 | Pentium MMX 223 MHz | 66MHz | 17W |
| P6 500nm | Socket 8 | Pentium Pro 200 MHz | 66MHz | 38W |
| Klamath 350nm | Slot 1 | Pentium II 300 MHz | 66MHz | 43W |
| Deschutes 250nm | Slot 1 | Pentium II 450 MHz | 100MHz | 27W |
| Katmai 250nm | Slot 1 SECC SECC2 | Pentium III 600 MHz | 133MHz | 27W |
| Coppermine 180nm | Slot 1 SECC2, Socket 370 | Pentium III 1133 MHz | 133MHz | 27W |
| Tualatin 130nm | Socket 370 | Pentium III S 1.40 GHz | 133MHz | 27W |
| Banias 130nm | Socket 479 | Pentium M | 400MHz | 24W |
| Dothan 90nm | Socket 479 | Pentium M | 533MHz | 21W |
| Yonah 65nm | Socket 478 (M) | Core Duo T2700 | 666MHz | 31W |
| Penryn 45nm | Socket 478 (P) | Core 2 Extreme QX9300 | 1066MHz | 45W |
Цікавим екземпляром мені бачиться зв'язка материнської плати ASUS P4P800 SE для P4 на чіпсеті 865PE, яка через перехідник ASUS CT-479 сумісна з процесорами Pentium M. Саме на цій платі можна побачити, що Pentium M швидші аналогічних процесорів Pentium 4.
Наступна архітектура була вже 64-бітною, ліцензованою у AMD і отримала назву EM64T, вперше з'явилися VT-x, SSE3. Ця архітектура досі живе в процесорах Intel і саме з процесорів Intel Core та чіпсетів X48 і P45 почнеться моя колекція.
Компактні клієнтські системи EM64T
Компактними ми називаємо системи з кількістю PCIe ліній менше ніж 32. Спочатку з Intel Core стало зрозуміло, що мости, відеокарти, корневі комплекси, котроллери пам'яті, когерентний кеш — все це краще розміщувати прямо на кристалічному процесорі. Багатопроцесорні системи стали однопакетними і популярною стала мінітюаризація, ринок наповнився Mini-ITX платами, а енергоефективність стала важливим показником на шляху прогресу.
| Platform | Lanes | PCIe/DMI ver | Motherboard | Generation |
|---|---|---|---|---|
| LGA775/P45 | 16 | 2.0/1.0x4 | P5Q SE PLUS | Core2 |
| LGA1156/H55 | 16 | 2.0/1.0x4 | P7H55 | 1 |
| LGA1155/H61 | 16 | 2.0/2.0x4 | P8H61-I | 2,3 |
| LGA1155/Z77 | 20 | 3.0/2.0x4 | P8Z77-I DELUXE | 2,3 |
| LGA1150/Z87 | 20 | 3.0/2.0x4 | Z87I-PRO | 4 |
| LGA1150/Z97 | 20 | 3.0/2.0x4 | Z97I-PLUS | 4,5 |
| LGA1151/Z170 | 24 | 3.0/3.0x4 | Z170I PRO GAMING | 6 |
| LGA1151/Z270 | 24 | 3.0/3.0x4 | STRIX Z270-I | 6,7 |
| LGA1151-2/Z370 | 24 | 3.0/3.0x4 | STRIX Z370-I | 8,9 |
| LGA1151-2/Z390 | 24 | 3.0/3.0x4 | STRIX Z390-I | 8,9 |
| LGA1200/Z490 | 24 | 4.0/3.0x8 | STRIX Z490-I | 10 |
| LGA1200/Z590 | 24 | 4.0/3.0x8 | STRIX Z590-I | 10,11 |
| LGA1700/Z690 | 24 | 5.0/4.0x8 | STRIX Z690-I | 12,13,14 |
| LGA1151/Z790 | 24 | 5.0/4.0x8 | STRIX Z790-I | 12,13,14 |
| LGA1851/Z890 | 24 | 5.0/4.0x8 | STRIX Z890-I | 15 |
Тут зібрано дев'ять плат на дев'яти чіпсетах, що покривають споживчі клієнтські процесори Intel. Це така гра: зібрати мінімальну кількість материнських плат, в які можна вставити будь-який процесор. Після Z370 я оновився до Z690, потім планую оновитися на наступний чіпсет після Z890, або плату на Z890, якщо вона буде підтримувати дві Core Ultra генерації 15 (Series 2) і 16 (Series 3). Поза увагою опинилися плати Z390, Z490, Z790.
Кожен сокет в номенклатурі ASUS має свій номер після бувки P: 1) Socket 8 (P1); 2) Slot 1 (P2); 3) Socket 370 (P3); 4) Socket 478 (P4); 5) LGA755 (P5); 6) LGA1366 (P6); 7) LGA1156 (P7); 8) LGA1155 (P8); 9) LGA1150 (P9); 10) LGA1151 (P10). До скайлейків, після цього нумерація перейшла на префікси чіпсетів Intel (X — воркстейшин без ECC, Z — клієнт без ECC, W — воркстейшин з ECC, С — клієнт з ECC) і власні імена типу STRIX, RAMPAGE, DOMINUS.
| Codename | Socket | Model | Cores/Threads | Lanes |
|---|---|---|---|---|
| Conroe, Yorkfield | LGA775 | X6800, QX9770 | 4/8 | — |
| Lynnfield | LGA1156 | i7-880 | 4/8 | — |
| Sandy Bridge | LGA1155 | i7-2700K | 4/8 | 16 |
| Ivy Bridge | LGA1155 | i7-3770K | 4/8 | 16 |
| Haswell, Devil's Canyon | LGA1150 | i7-4790K, E5-4669V3 | 4/8 | 16 |
| Broadwell | LGA1150 | i7-5775C, E5-2699V4 | 4/8 | 16 |
| Skylake | LGA1151 | i7-6700K | 4/8 | 16 |
| Kaby Lake | LGA1151 | i7-7700K | 4/8 | 16 |
| Coffee Lake | LGA1151-2 | i7-8700K | 6/12 | 16 |
| Coffee Lake Refresh | LGA1151-2 | i7-9700K | 8/8 | 16 |
| Comet Lake | LGA1200 | i7-10700K | 8/16 | 16 |
| Rocket Lake | LGA1200 | i7-11700K | 8/16 | 16 |
| Alder Lake | LGA1700 | i7-12700K | 12(8+4)/20 | 20 |
| Raptor Lake | LGA1700 | i7-13700K | 16(8+8)/24 | 20 |
| Raptor Lake Refresh | LGA1700 | i7-14700K | 20(8+12)/28 | 20 |
| Meteor Lake (Series 1) | BGA2049 | 155H | 16(6+10)/22 | 24 |
| Arrow Lake (Series 2) | LGA1851 | 285K | 24(8+16)/24 | 24 |
Повний перелік всіх емісій процесорів на 14нм техпроцесі (6-9 покоління) дивіться в дослідженні Intel Skylake.
Робочі станції
Робочими станціями ми називаємо системи з кількістю PCIe ліній більше ніж 32 (SLI). На ринку серверних процесорів збільшення ядер йшло ще більш бадьорими темпами, для збільшення кількості PCIe ліній, потрібно було більше ядер, і це стало основним пріоритетом для еволюції дійсно багатоядерних архітектур.
| Platform | Lanes | PCIe/DMI | Motherboard | Generations |
|---|---|---|---|---|
| LGA775/X38 | 36 | 2.0/1.0x4 | P5E64 WS PRO | Core2 |
| LGA775/X48 | 36 | 2.0/1.0x4 | RAMPAGE I | Core2 |
| LGA775/X48 | 36 | 2.0/1.0x4 | RAMPAGE I DDR3 | Core2 |
| LGA1366/X58 | 36 | 2.0/2.0x4 | P6T7 WS SC | Nehalem (NHM-EP, WSM-EP) |
| LGA1366/X58 | 36 | 2.0/2.0x4 | RAMPAGE II | Nehalem (NHM-EP, WSM-EP) |
| LGA1366/X58 | 36 | 2.0/2.0x4 | RAMPAGE III | Nehalem (NHM-EP, WSM-EP) |
| LGA2011/X79 | 40 | 3.0/2.0x4 | P9X79 WS | Romley (SNB-E, IVB-E) |
| LGA2011/X79 | 40 | 3.0/2.0x4 | RAMPAGE IV | Romley (SNB-E, IVB-E) |
| LGA2011-3/X99 | 40 | 3.0/2.0x4 | RAMPAGE V | Grantley (HSW-E, BDW-E) |
| LGA2066/X299 | 48 | 3.0/3.0x4 | RAMPAGE VI | Basin Falls (SKL-X, CSL-X) |
| LGA3647/C621 | 64 | 3.0/3.0x4 | DOMINUS | Purley (CSL-W, CSL-SP) |
| LGA4189/C621A | 64 | 4.0/3.0x4 | C621A WS | Whitley (ICL-SP), Cedar Island |
| LGA4677/W790 | 80 | 5.0/4.0x8 | WS W790-ACE | Eagle Stream (SPR-SP, EMR-SP) |
| LGA7529/W890 | 136 | 5.0/4.0x8 | – | Birch Stream (GNR-SP, SRF-SP) |
| LGA1156/3450 | 36 | 2.0/2.0x4 | P7F7-E WS SC | 1 |
| LGA1156/P55 | 32 | 2.0/1.0x4 | P7P55 WS SC | 1 |
| LGA1155/C206 | 32 | 3.0/2.0x4 | P8B WS | 2,3 |
| LGA1155/C216 | 32 | 2.0/1.0x4 | P8C WS | 2,3 |
| LGA1150/C224 | 32 | 3.0/3.0x4 | P9D-M | 4 |
| LGA1150/C226 | 32 | 3.0/3.0x4 | P9D WS | 4 |
| LGA1366/5500 | 32 | 3.0/2.0x4 | Z8NA-D6 | 4,5 |
| LGA2011/C602 | 32 | 3.0/2.0x4 | Z9PE-D8 WS | 4,5 |
| LGA2011-3/C612 | 32 | 3.0/2.0x4 | Z10PE-D16 WS | 4,5 |
| LGA1151/C236 | 32 | 3.0/3.0x4 | P10S WS | 6,7 |
| LGA1151/C246 | 32 | 3.0/3.0x4 | Pro WS C246-ACE | 8,9 |
Архів робочих станцій (PCIe 2.0) починається для сокета 775 на чіпсеті X48. Кожна з них подвоює число доступних PCIe у порівнянні з клієнтськими платформами.
Xeon Scalable (Platinum 8x80) процесори для робочих станцій випускалися для сокетів: LGA3647 (1-SKL, 2-CSL), LGA4189 (3-ICL), LGA4677 (4-SPR, 5-EMR), були окремі емісії процесорів в сегменті робочих станції (Xeon W). Процесори Xeon на ядрах після Sunny Cove ведуть свій родовід не від Pentium Pro (P6), а від багатоядерних Xeon Phi (Knights Landing), де кожне ядро — це Atom процесор (E-core починаючи з 12 серії), представлений раніше як енергоефективний x86 конкурент ARM процесора. З початком Skylake перша генерація отримала продуктивні P6 ядра (P-core починаючи з 12 серії).
З початком Sierra Forest процесори Xeon Scalable знов випускаються у варіації лише з E-core ядрами (як Xeon Phi). Але Xeon 6 процесори потребують нових сокетів LGA7529 (Granite Rapids) і LGA4710 (Sierra Forest). Emerald Rapids підтримують той самий сокет, що ї Sapphire Rapids.
| Codename | Socket | Model | Cores/Threads | Lanes |
|---|---|---|---|---|
| Core X 2009 | LGA1366 | i7-975EE | 6/12 | — |
| Core X 2011 | LGA1366 | i7-990X | 6/12 | — |
| Core X 2012 | LGA2011 | i7-3970X SNB | 6/12 | 40 |
| Core X 2013 | LGA2011 | i7-4960X IVB | 6/12 | 40 |
| Core X 2014 | LGA2011 | i7-5960X HSW | 8/16 | 40 |
| Core X 2016 | LGA2011 | i7-6950X BDW | 10/20 | 40 |
| Core X 2017 | LGA2066 | i9-7980XE SKL | 18/36 | 44 |
| Core X 2018 | LGA2066 | i9-9980XE SKL | 18/36 | 44 |
| Core X 2019 | LGA2066 | i9-10980XE CSL | 18/36 | 48 |
| Xeon E | LGA1700 | E-2468 RPL | 8/8 | 20 |
| Xeon E | LGA1200 | E-2378 RTL | 8/16 | 20 |
| Xeon E | LGA1200 | E-2378 RTL | 8/16 | 20 |
| Xeon E | LGA1151 | E-2136 CFL | 8/16 | 16 |
| Xeon W 2017 | LGA2066 | W-2195 SKL | 18/36 | 48 |
| Xeon W 2018 | LGA3647 | W-3175X SKL | 28/56 | 48 |
| Xeon W 2019 | LGA2066 | W-2295 CSL | 18/36 | 48 |
| Xeon W 2019 | LGA3647 | W-3275 CSL | 28/56 | 64 |
| Xeon W 2021 | LGA4189 | W-3375 ICL | 38/76 | 64 |
| Xeon W 2023 | LGA4677 | w9-3495X SPR | 56/112 | 112 |
| Xeon W 2024 | LGA4677 | w9-3595X SPR | 60/120 | 112 |
| Skylake (1-st, 2017) | LGA3647 | Platinum 8180 | 28/56 | 48 |
| Cascade Lake (2-nd, 2019) | LGA3647 | Platinum 8280 | 28/56 | 48 |
| Ice/Cooper Lake (3-rd, 2021) | LGA4189 | Platinum 8380 | 28/56 | 64 |
| Sapphire Rapids (4-th, 2024) | LGA4677 | Platinum 8480+ | 56/112 | 80 |
| Emerald Rapids (5-th, 2024) | LGA4677 | Platinum 8592+ | 64/128 | 80 |
| Sierra Forest (6-th, 2025) | LGA4710 | Xeon 6780E | 144/144 | 88 |
| Granite Rapids (6-th, 2025) | LGA7529 | Xeon 6980P | 128/256 | 96 |
AMD почала випускати енергоефективні багатоядерні (від 32) процесори на Zen 3 архітектурі лише через 8 років (2020) після появи Xeon Phi процесорів (2012). Зате одразу дали 88 PCIe ліній, версію 4.0 і без пропрієтарного мосту (DMI), майже всі лінії заведені одразу на кореневий комплекс.

Intel довелося зробити крок у відповідь на Threadripper і випустити 10-е покоління Cascade Lake для платформи X299, щоб продовжити свій цейтнот. Я думаю спеціально для цієї емісії 10-го покоління X-серії ASUS випустила додаткову серію плат RAMPAGE VI, підкреслюючи швидкоплинний момент HEDT (High-End Desktop) платформи з процесорами Core X.
E-Cores (Atom) і P-Cores (P6)
| Codename | Mobile | Client | Server | |
|---|---|---|---|---|
| Silvermont (1) | Bay Trail | Atom | Knights Landing | |
| Goldmont (2) | Denverton | Apollo Lake | Pentium Silver | |
| Tremont (3) | Lakefield | — | Snow Ridge | |
| Gracemont (4) | — | Alder Lake | — | |
| Crestmont (5) | — | Meteor Lake | Sierra Forest | |
| Skymont (6) | Lunar Lake | Arrow Lake | — | |
| Sheldonmont (7) | — | — | Cooper Forest | |
| Darkmont (8) | — | — | Clearwater Forest | |
| Palm Cove (KBL) | Cannon Lake | — | — | |
| Sunny Cove (1) | Lakefield | Comet Lake | Ice Lake, Cooper Lake | |
| Cypress Cove (2) | Tiger Lake | Rocket Lake | Xeon E-2300, W-1300 (8/16) | |
| Golden Cove (3) | — | Alder Lake | Sapphire Rapids | |
| Raptor Cove (4) | — | Raptor Lake | Emerald Rapids | |
| Redwood Cove (5) | Meteor Lake | — | Granite Rapids | |
| Lion Cove (6) | Lunar Lake | Arrow Lake | — | |
| Panther Cove (7) | Panther Lake | Nova Lake | Diamond Rapids | |
| Douglas Cove (8) | — | Adams Lake | — | |
[1]. Intel® 200 Series: B250, Q250, H270, Q270, Z270, X299, Z370 PCHs #1
[2]. Intel® 200 Series: B250, Q250, H270, Q270, Z270, X299, Z370 PCHs #2
Відеокарти
Що стосується експериментів із системами індексації, які розташовуються в пам'яті GPU, то тут має сенс гратиcя тільки з пам'яттю від 10ГБ, тобто не нижче 1080 Ti.
| Model | PCIe | Chip | Memory | Process | Transistors |
|---|---|---|---|---|---|
| GTX 780 Ti | 3.0 | GK110 | 3GB DDR5 | 28nm | 7080M |
| GTX 980 Ti | 3.0 | GM200 | 6GB DDR5 | 28nm | 8B |
| GTX 1080 Ti | 3.0 | GP102 | 11GB DDR5 | 16nm | 12B |
| RTX 2080 Ti | 3.0 | TU102 | 11GB DDR6 | 12nm | 18.6B |
| RTX 3090 | 4.0 | GA102 | 24GB DDR6 | 8nm | 28B |
| RTX 4070 Ti Super | 5.0 | AD104 | 24GB DDR6 | 4nm | 35B |
Відеокарти — це другий вид обчислювальних потужностей після CPU. Сучасні комп'ютери є аналогом таких систем як BeBox або Cell/BE, які можуть поєднувати обчислювальні CISC, RISC, SIMD або VLIW блоки. Процесори відеокарт називаються GPU і, як і звичайні процесори CPU, мають свій набір інструктій і свою локальну пам'ять. Аналог інструкції MOV виступає команда копіювання в/з DMA буфера DDR пам'яті по PCIe. Як і в CPU, в GPU є ALU інструкції (додавання, множення) та інструкції управління потоками виконання.
CUDA и RDNA
Головні ядра CUDA [1] називаються потоковими процесорами (SM), їхня кількість визначає продуктивність. Кожен SM складається з багатьох скалярних процесорів, кожен із яких можна виділити для обробки вершин, фіугр, або пікселів. Для управління скалярними процесорами як потоками виконання використовується високорівнева модель паралельного програмування на кшталт SIMD, лише джерела й цілі операцій це клітинки пам'яті, а потоки виконання — SIMT.
У картах AMD використовується інший набір інструкцій [2], але дуже схоже. Буфери пам'яті поділяються на три типи: вершини, фігури та пікселі. Команди GPU - це обчислення, які використовують один тип пам'яті як джерело, і інший тип пам'яті як мета команди. Вершинні шейдери роблять обчислення на вершинах і записують результат у кільцевий буфер примітивів (масиви фігур). Геометричні шейдери проводять обчислення на буферах геометричних примітивів і записують результат на згадку про фрагменти, які представляють собор розтеризований шматок екрану в буфері. Фрагмен стає пікселем, коли переноситься в реальний буфер екрану (піксельні шейдери). На кожному етапі такого пайпа лайна обчислювальні ядра користуються текстурами, які вже завантажені в пам'ять GPU.
[1]. PTX ISA 7.0 (2020)
[2]. RDNA ISA 1.0 (2020)
[3]. CMU CS 15-462 Lecture 19 (2011)
Дискові масиви
Для експериментів у рамках проекту RocksDB/NVMe нам знадобляться карти PCIe x16 (4 слоти M.2 кожен по x4 лінії), для версій PCIe 3.0 та 4.0. Кожна така карта конфігурується як RAID-0 масив і таким чином збільшується швидкість передачі лінійно в 4 рази. Нам потрібні саме RAID-0 масиви, тому що продуктивність – це головна мотивація проекту RocksDB/NVMe. Звичайно, такі карти це потрібно вставляти в PCIe слот, підключений безпосередньо до кореневого комплексу, а не до пропрієтарного мосту для підключення периферії. Зазвичай половина слотів (а на mITX іноді і все) M.2 розташовані на материнських платах платформи Intel, підключені саме по такій шині DMI, яка має пропускну здатність всього 4 PCIe лінії, тому RAID-0 на таких слотах будувати сенсу немає. У випадку ATX і EATX плат для побудови RAID-0 найкраще вставляти плати розширення для M.2 масивів у PCIe x16 слоти, підключені до кореневого комплексу. У разі mITX систем доведеться витягувати тимчасово GPU і вставляти M.2 RAID-0 в єдиний x16 слот.
M.2 Hyper x16 SW VROC RAID
M.2 слоти підключені до пропрієтарного мосту DMI, можна використовувати для поодиноких x4 NVMe інстансів, як завантажувальні диски для альтернативних ОС і т.д. Я планую використати Haiku, FreeBSD, Linux, Windows. Не пропадати ж M.2 слотам.
SATA VDM HW RAID-0
Є ще варіант використання RocksDB/SATA: будуємо масив на дисках, максимальна пропускна спроможність яких лише 600МБ/c. Для цього на mITX системах можна побудувати масив із 3-4 дисків, а для великих ATX/EATX систем я раджу купувати материнські плати, де є 10 портів SATA. Ці 10 портів зазвичай використовують для RAID систем, але не апаратних (бо відновлювати будь-який RAID це нетривіальне завдання), а програмних комплексів типу Unraid, Ceph, GlusterFS. Ceph до речі використовує RocksDB/NVMe бекенд для одного з типів своїх сховищ BlueStore). Ці системи пропонують зручніший ніж апаратний спосіб роботи з масивами: якщо один диск полетів, ви просто його витягуєте і вставляєте новий.
Твердотілі накопичувачі не варто використовувати для бекапа. Замість механічних та SSD накопичувачів зазвичай для бекапа використовували магнітні стрічки або магнітооптику, яка досі є найактуальнішим способом зберігання даних, як, наприклад SONY PRO ODS-D380U.
За 10 років ціна на SSD знизилася з $1 за 1ГБ до $1 за 10ГБ. Твердотільні накопичувачі NVMe складаються з DRAM кешу, SLC кешу та зазвичай 64-шарових TLC або QLC чіпів. Деякі виробники (ADATA, Transcend) використовують технологію HMB і постачають диски без DRAM кешу, натомість передбачається використання пам'яті хоста, яка підключена до PCIe. Такі диски не працюють у Thunderbolt перехідниках USB-to-PCIe. Потрібно купувати тільки ті NVMe, які пропонують показники продуктивності близькі до теоретичної межі PCIe 3.0 x4 (3938.5МБ/с), і максимально не залежать від об'єму даних, що передаються (SLC кеш), DRAM кеш на 1Т зазвичай становить 1ГБ. У 2020 році купувати NVMe менше 1Т сенсу немає, вони швидше, у них більше SLC кешу, якісніші мікросхеми, вигідна питома вартість одиниці обсягу.
| Model | PCIe | Size | Chip | Flash | MB/s | Lifetime |
|---|---|---|---|---|---|---|
| Samsung 970 EVO+ | 3.0 x4 | 1T | Samsung Phoenix | 64 TLC Samsung 256G | 3500/3300 | 600T |
| Samsung 970 PRO | 3.0 x4 | 1T | Samsung Phoenix | 64 MLC Samsung 256G | 3500/3300 | 1200T |
| WS Black SN750 | 3.0 x4 | 1T | SanDisk | 64 TLC SanDisk 256G | 3470/3000 | 600T |
| Patriot VPN100 | 3.0 x4 | 1T | Phison PS5012-E12 | 64 TLC Toshiba 256G | 3450/3000 | 1665T |
| Intel 760P | 3.0 x4 | 1T | SMI SM2262 | 64 TLC Intel 256G | 3230/1625 | 576T |
| ATADA XPG S11 Pro | 3.0 x4 | 1T | SMI SM2262EN | 64 TLC Micron 512G | 3500/3000 | 640T |
| MTE220S | 3.0 x4 | 1T | SMI SM2262EN | 64 TLC Micron 512G | 3500/2800 | 640T |
| Kingston KC2000 | 3.0 x4 | 1T | SMI SM2262EN | 96 TLC Toshiba 512G | 3200/2200 | 600T |
| Sabrent Rocket | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 5000/4400 | 1800T |
| Corsair MP600 | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 4950/2500 | 1800Т |
| FireCUDA 520 | 4.0 x4 | 1T | 96 TLC Toshiba 512G | 5000/4400 | 1800Т | |
| GAMMIX S50 | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 5000/4400 | 1800Т |
Колекційними вважаються чотирьохканальні RAID-0 переходники на 16 ліній PCIe, тобто чотири диски (якшо менше — не беріть). Якщо на материнській платі залишаються вільні слоти х8 і хочеться їх використовувати для RAID, то можна використовувати адаптери x8 M.2 на двох дисках.
| Model | PCIe |
|---|---|
| ASUS Hyper M.2 Gen5 | 5.0 x16 |
| ASUS Hyper M.2 V2 | 3.0 x16 |
| ASUS Hyper M.2 | 4.0 x16 |
| ASRock ULTRA QUAD | 3.0 x16 |
| AORUS Gen4 AIC | 4.0 x16 |
| Startech x8 Dual M.2 | 3.0 x8 |
| Sonnet M.2 4x4 | 3.0 x8 |
| Synology M2D18 | 4.0 x8 |
[1]. SPDK.IO/DOC
[2]. NVMe 1.4
[3]. Yan Beyer. A fast kvstore based on spdk programing framework.
[4]. T.Yoshimura, T.Chiba, H.Horii. EvFS: User-level, Event-Driven File System for Non-Volatile Memory.
Корпуса
Як видно з таблиць, всі плати можна розділити на дві категорії: малі та великі. У категорії малих корпусів мені найбільше сподобалися DeepCool Tristellar, NZXT H200i, AZZA Pyramyd 804. Для повнорозмірних великих CEB/EEB/XLATX плат Lian Li O11D XL, а для EATX плат і дискових масивів DeepCool Quadstellar. Усього 5 корпусів. Якщо вистачає грошей, можна ще купити стіл Lian Li.
Операційні системи
| Motherboard | Windows NT version |
|---|---|
| ConRoe945G-DVI | Windows Vista (6.0.6000) |
| ConRoeXFire-eSATA2 | Windows Vista (6.0.6000) |
| P4P800 SE | Windows XP (5.1.2600) |
| P5Q SE PLUS | Windows 7 (6.1.7600) |
| P6T7 WS SC | Windows 7 (6.1.7600) |
| P7P55 WS SC | Windows 7 (6.1.7600) |
| P8H61-I | Windows 7 (6.1.7600) |
| P9X79 WS | Windows 8.1 (6.3.9600) |
| P9D-M | Windows 8.1, Server 2012 R2 (6.3.9600) |
| RAMPAGE I | Windows 7 (6.1.7600) |
| RAMPAGE VI | Windows 11 (10.0.22000.100) |
| STRIX Z370-I | Windows 10 (10.0.10240) |
| STRIX Z690-I | Windows 11 (10.0.22000.100) |